DeepSeek-V3 & R1: A Deep Dive into Architecture, Training and Implications for the Future of AI
This deep-dive into the research paper explores DeepSeek-V3 & R1, a powerful and efficient open-source language model built on a Mixture-of-Experts (MoE) architecture. DeepSeek models introduces several innovations, including Multi-head Latent Attention and auxiliary-loss-free load balancing, to achieve state-of-the-art performance on various tasks while being remarkably cost-effective. The paper also delves into the training process and implications on the future of AI, including its potential to democratize access to advanced AI capabilities.
TECH DRIVEN FUTURE
1/28/20259 min read
DeepSeek-V3, a large language model (LLM) developed by the Chinese AI startup DeepSeek, has sent shockwaves through the global tech industry. Its release triggered a market crash, wiping out trillions of dollars in market capitalization and particularly impacting giants like NVIDIA. This LLM, lauded for its efficiency, open-source nature and impressive capabilities, has disrupted the AI landscape and raised questions about the investment strategies of both startups & established AI companies. The research paper provides a comprehensive overview of DeepSeek-V3, delving into its key features, training process and implications for the future of AI.
A Strong and Efficient Mixture-of-Experts Language Model
DeepSeek-V3 is a powerful and efficient open-source LLM built on a Mixture-of-Experts (MoE) architecture. It boasts 671 billion parameters, with 37 billion activated per token and has been trained on a massive dataset of 14.8 trillion high-quality tokens. This enables DeepSeek-V3 to excel in various tasks, including code generation, mathematical reasoning and natural language processing.
One of DeepSeek-V3's most notable features is its innovative use of synthetic data for coding and math tasks, combined with knowledge distillation from its predecessor, DeepSeek-R1, a model focused on reasoning capabilities. This approach has significantly contributed to its remarkable efficiency and performance.
Purpose and Problem
The primary purpose of DeepSeek-V3 is to push the boundaries of open-source language models, offering a strong, efficient and cost-effective alternative to closed-source models. The research aims to address the following challenges:
Improving Model Performance: DeepSeek-V3 seeks to achieve better performance on a wide range of tasks, including language understanding, reasoning, code generation and math problem-solving.
Enhancing Training Efficiency: The research focuses on developing efficient training frameworks and techniques to reduce the computational cost and environmental impact of training large language models.
Optimizing Inference and Deployment: DeepSeek-V3 aims to achieve efficient inference and deployment strategies to make the model practical for real-world applications.
Key Features and Innovations
DeepSeek-V3 incorporates several key features and innovations that contribute to its strong performance and efficiency:
Multi-head Latent Attention (MLA)
MLA is a novel attention mechanism that enables efficient inference by reducing the Key-Value (KV) cache size. In traditional Multi-Head Attention (MHA), the KV cache stores all keys and values for each token, which can become prohibitively large for long sequences. MLA addresses this by performing low-rank joint compression of keys and values, significantly reducing the KV cache size while maintaining comparable performance to MHA.
DeepSeekMoE
DeepSeekMoE is an innovative architecture that allows for cost-effective training by using finer-grained experts and isolating some experts as shared ones. In traditional MoE models, each token is routed to a subset of experts for processing. DeepSeekMoE improves upon this by using a larger number of smaller experts, allowing for more specialized expertise and better load balancing. Additionally, some experts are designated as shared experts, processing all tokens and providing a global context.
Auxiliary-loss-free Load Balancing
This strategy ensures balanced expert load during training without relying on auxiliary losses that can impair model performance. Traditional MoE models often use auxiliary losses to encourage load balancing, but these losses can negatively impact the model's ability to learn the primary objective. DeepSeek-V3 introduces an auxiliary-loss-free load balancing strategy that dynamically adjusts expert routing based on load, achieving balanced load without sacrificing performance.
Multi-token Prediction (MTP) Training Objective
This objective enhances overall performance by extending the prediction scope to multiple future tokens at each position. In traditional language modeling, the model predicts only the next token in the sequence. MTP extends this by predicting multiple future tokens, providing denser training signals and potentially enabling the model to pre-plan its representations for better prediction.
FP8 Mixed Precision Training
This framework utilizes the FP8 data format for training, achieving both accelerated training and reduced GPU memory usage. FP8 is a lower-precision data format compared to the commonly used FP32 or BF16 formats. By using FP8 for most compute-intensive operations, DeepSeek-V3 achieves faster training and reduces memory consumption, enabling training on larger datasets and models.
DualPipe Algorithm
This algorithm enables efficient pipeline parallelism with fewer pipeline bubbles and near-zero all-to-all communication overhead. Pipeline parallelism is a technique for distributing model training across multiple GPUs, but it can suffer from pipeline bubbles, where some GPUs are idle while waiting for others. DualPipe addresses this by carefully scheduling computation and communication, minimizing pipeline bubbles and overlapping communication with computation.
Training Process
DeepSeek-V3 undergoes a multi-stage training process:
Data Construction
The training corpus for DeepSeek-V3 consists of 14.8 trillion high-quality and diverse tokens, carefully curated and processed to minimize redundancy and maintain diversity. The corpus includes a mix of text and code data, with an emphasis on mathematical and programming samples to enhance the model's capabilities in these domains.
Hyperparameter Setting
The model and training hyperparameters are carefully tuned to achieve optimal performance and efficiency. The model architecture consists of 61 Transformer layers with a hidden dimension of 7168. The MoE layers activate 8 experts per token, with each token routed to a maximum of 4 nodes. The training process utilizes the AdamW optimizer with a learning rate schedule that gradually increases and then decays.
Long Context Extension
After the initial pre-training stage, DeepSeek-V3 undergoes a two-stage context length extension process, progressively expanding the maximum context window from 4K to 32K and then to 128K. This enables the model to handle longer input sequences and maintain strong performance on tasks that require processing large amounts of information.
Post-Training
The post-training stage involves Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) to align the model with human preferences and further unlock its potential. SFT fine-tunes the model on a dataset of human-generated instructions, while RL trains the model to maximize rewards based on human feedback. This process enhances the model's ability to follow instructions, generate high-quality responses and perform well on a variety of tasks.
Performance and Evaluation
DeepSeek-V3 has been evaluated on a comprehensive array of benchmarks, demonstrating state-of-the-art performance on many tasks.
Knowledge
DeepSeek-V3 outperforms all other open-source models on educational benchmarks such as MMLU, MMLU-Pro and GPQA. It also shows superior performance on factuality benchmarks, including SimpleQA and Chinese SimpleQA.
Code, Math and Reasoning
DeepSeek-V3 achieves state-of-the-art performance on math-related benchmarks among all non-long-CoT open-source and closed-source models. It also excels in coding competition benchmarks, such as LiveCodeBench and demonstrates competitive performance on engineering-related tasks.
DeepSeek-R1: A Reasoning-Focused LLM
DeepSeek-R1 is a groundbreaking language model that pushes the boundaries of reasoning capabilities in large language models (LLMs). This research paper delves into the development of DeepSeek-R1, highlighting its innovative use of reinforcement learning (RL) and knowledge distillation to achieve impressive performance on complex reasoning tasks.
The primary purpose of DeepSeek-R1 is to enhance the reasoning capabilities of LLMs, enabling them to solve complex problems that require logical thinking and step-by-step analysis. The research aims to address the following challenges:
Improving Reasoning Performance: DeepSeek-R1 seeks to achieve better performance on a wide range of reasoning tasks, including mathematics, coding, and logical reasoning.
Exploring Self-Evolution through RL: The research focuses on exploring the potential of LLMs to develop reasoning capabilities without relying on supervised data, focusing on their self-evolution through a pure RL process.
Enhancing Readability and User-Friendliness: DeepSeek-R1 aims to address the issues of poor readability and language mixing encountered in earlier models, making the reasoning process more transparent and user-friendly.
Empowering Smaller Models with Reasoning Capability: The research explores knowledge distillation techniques to transfer the reasoning capabilities of DeepSeek-R1 to smaller, more efficient models.
DeepSeek-R1-Zero: Reinforcement Learning on the Base Model
DeepSeek-R1-Zero is a preliminary model developed using a pure RL approach without any supervised fine-tuning (SFT). This model demonstrates remarkable reasoning capabilities, showcasing the potential of LLMs to self-evolve and learn complex reasoning strategies through RL.
The training process involves using a rule-based reward system that evaluates the accuracy and format of the model's responses. The model is trained to generate a reasoning process, enclosed within <think> and </think> tags, followed by the final answer, enclosed within <answer> and </answer> tags.
DeepSeek-R1-Zero exhibits significant improvement in performance on reasoning benchmarks as training progresses. For instance, the pass@1 score on AIME 2024 increases from 15.6% to 71.0%, reaching performance levels comparable to OpenAI-01-0912.
DeepSeek-R1: Reinforcement Learning with Cold Start
DeepSeek-R1 builds upon the successes of DeepSeek-R1-Zero by incorporating a small amount of cold-start data and a multi-stage training pipeline. This approach addresses the limitations of DeepSeek-R1-Zero, such as poor readability and language mixing, while further enhancing reasoning performance.
The training process involves four stages:
Cold Start: A small amount of long chain-of-thought (CoT) data is used to fine-tune the base model, providing a more stable starting point for RL.
Reasoning-Oriented RL: RL is applied to the fine-tuned model, focusing on enhancing reasoning capabilities in tasks like coding, mathematics, and logical reasoning.
Rejection Sampling and Supervised Fine-Tuning: Rejection sampling is used to curate high-quality SFT data from the RL checkpoint, combined with supervised data from other domains to enhance general capabilities.
Reinforcement Learning for All Scenarios: A secondary RL stage is implemented to further align the model with human preferences, improving helpfulness and harmlessness while refining reasoning capabilities.
This multi-stage training pipeline results in DeepSeek-R1, a model that achieves performance on par with OpenAI-01-1217 on a range of tasks.
Distillation: Empowering Smaller Models with Reasoning Capability
To make reasoning capabilities more accessible, DeepSeek-R1's knowledge is distilled into smaller, more efficient dense models. This is achieved by fine-tuning open-source models like Qwen and Llama using the curated dataset from DeepSeek-R1.
The results are impressive, with the distilled models achieving significantly better performance compared to their original versions. For instance, DeepSeek-R1-Distill-Qwen-7B outperforms GPT-40-0513 across the board, and DeepSeek-R1-Distill-Qwen-32B achieves 72.6% on AIME 2024, 94.3% on MATH-500, and 57.2% on LiveCodeBench, surpassing previous open-source models and rivaling o1-mini.
More details from research
The research also discusses the trade-off between distillation and RL, highlighting the effectiveness of distilling knowledge from larger models while acknowledging the potential of RL to further push the boundaries of intelligence.
Additionally, the paper shares insights from unsuccessful attempts, including the use of Process Reward Model (PRM) and Monte Carlo Tree Search (MCTS), providing valuable lessons for future research in reasoning-focused LLMs.
Implications for the Future of AI
DeepSeek’s models represents a significant advancement in open-source language models, offering a strong and efficient alternative to closed-source models. Its innovations in architecture, training and deployment have implications for the future of AI:
Democratizing Access to Powerful AI: DeepSeek makes powerful AI capabilities more accessible to researchers, developers and smaller teams who may not have the resources to train or deploy large closed-source models.
Driving Innovation in AI Research: The open-source nature encourages collaboration and knowledge sharing, fostering innovation in AI research.
Promoting Responsible AI Development: By making the model's architecture and training data transparent, it promotes responsible AI development and helps address concerns about bias and fairness.
Reducing the Environmental Impact of AI: The efficient training and deployment strategies contribute to reducing the environmental impact of AI.
Why has it shocked the world?
DeepSeek-V3 & R3's cost-effectiveness and remarkable performance using less advanced hardware raised questions about whether established AI companies inflated the need for substantial investments in AI infrastructure. Some experts argued that these companies might have overestimated the resources required to develop advanced AI models, potentially misleading investors and governments to maintain a competitive edge or justify high prices for their AI services.
DeepSeek, with a total investment of only $50 million, achieved comparable performance to leading models while utilizing less expensive hardware like the NVIDIA H800, a less powerful version of the H100 used by many US companies. This frugal approach challenges the narrative of massive spending being essential for AI development.
Furthermore, the US government's restrictions on chip exports to China might have inadvertently motivated DeepSeek to innovate and find ways to achieve high performance with less advanced resources. This raises questions about whether the pursuit of cutting-edge technology and the associated costs are always necessary for achieving significant advancements in AI.
DeepSeek's success has raised questions on the need for huge AI investment plans from Tech Giants. The projects, previously seen as ambitious but necessary, now will possibly face the heat regarding their potential returns and the possibility of overspending.
However, it's crucial to acknowledge that developing and deploying advanced AI models involves various costs beyond hardware, including research and development, data acquisition and talent acquisition. While DeepSeek demonstrated remarkable efficiency, it might not fully represent the complexities and costs associated with developing and maintaining cutting-edge AI models at scale.
Conclusion
DeepSeek-R1 is a pioneering LLM that showcases the power of RL and knowledge distillation in enhancing reasoning capabilities. Its open-source nature, multi-stage training pipeline, and impressive performance on various reasoning tasks have significant implications for the future of AI:
Advancement in Reasoning-Focused LLMs: DeepSeek-R1 pushes the boundaries of reasoning capabilities in LLMs, opening up new possibilities for solving complex problems that require logical thinking and step-by-step analysis.
Democratization of Reasoning Capabilities: The open-source nature of DeepSeek-R1 and its distilled versions makes advanced reasoning capabilities more accessible to researchers, developers, and smaller teams.
Efficient and Scalable Training: The innovative use of RL and knowledge distillation offers efficient and scalable approaches to training reasoning-focused LLMs.
Enhanced Transparency and User-Friendliness: DeepSeek-R1 addresses the limitations of earlier models, making the reasoning process more transparent and user-friendly.
DeepSeek’s models emergence as a powerful and efficient AI model has undeniably shaken the tech world. The market crash triggered by its release has raised a lot of questions in the AI industry, particularly the overreliance on expensive infrastructure and the potential for overblown investment expectations. While the long-term impact of DeepSeek's models remains to be seen, its emphasis on openness, efficiency and collaboration has set a new precedent for AI development, paving the way for a more accessible and sustainable future for artificial intelligence.
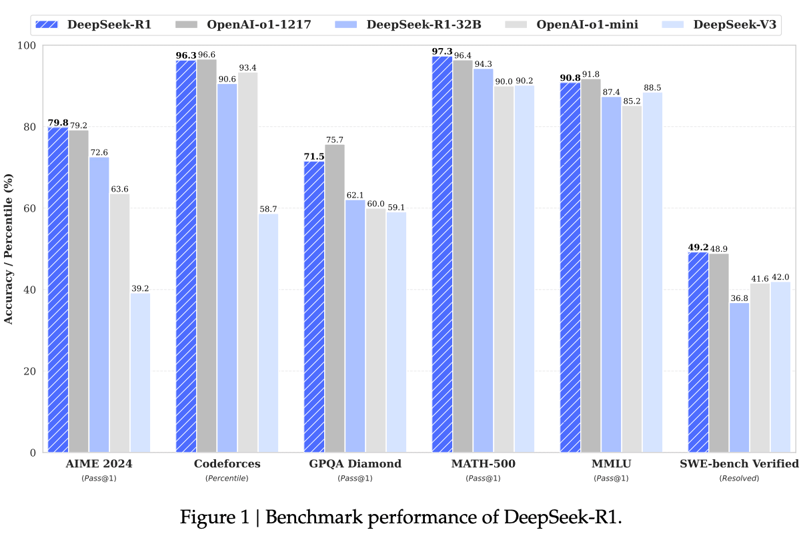
Source: Deepseek R1 research paper