Sakana AI's Transformer²: A Leap Forward in Self-Adaptive LLMs
Transformer² revolutionizes LLMs with its dynamic adaptability. Inspired by nature, this approach offers significant advantages over traditional methods, including enhanced efficiency, reduced overfitting and dynamic scaling. Learn how Transformer² paves the way for the development of truly dynamic and self-organizing AI systems.
TECH DRIVEN FUTURE
1/19/20254 min read
Imagine an AI system that learns and evolves like a living organism, dynamically adapting to new challenges and environments. Sakana AI's research paper explains a new Transformer² framework - a groundbreaking approach to enhancing large language models (LLMs) . It empowers LLMs to adjust their internal workings in real-time, optimizing their performance for a wide range of tasks without the need for extensive retraining.
Sakana AI: Pioneers of Nature-Inspired AI
Based in Tokyo, Japan, Sakana AI derives its name from the Japanese word for "fish". This is fitting, as the company draws inspiration from nature – particularly the collective intelligence of fish schools – to develop innovative AI models. Their team, composed of leading AI researchers from around the globe, believes in building AI systems that are not just powerful but also adaptable and efficient. This philosophy is evident in their recent work on evolutionary model merging, discovering diverse agentic skills and exploring new ways for LLMs to contribute to AI research. These efforts highlight Sakana AI's commitment to exploring diverse and innovative approaches to enhance LLMs, aligning with their nature-inspired philosophy. With strong financial backing and a global approach to talent acquisition, Sakana AI is well-positioned to make a significant impact on the AI landscape.
Understanding Transformer²
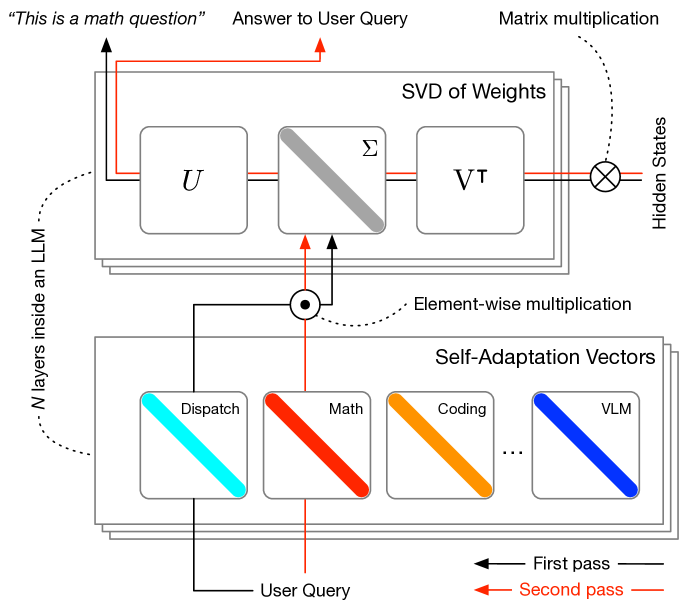
Transformer² employs a unique two-step process to achieve dynamic adaptation in LLMs . This process can be visualized as the model taking two passes at a prompt, first to understand the task and then to generate the appropriate response.
Step 1: Singular Value Fine-tuning (SVF)
Think of an LLM as having different "brain" components, each specialized for certain tasks. Singular Value Fine-tuning (SVF) acts like a conductor, selectively amplifying or dampening these components based on the task at hand . This is achieved through reinforcement learning (RL), where the model learns to adjust critical components of its weight matrices – essentially the connections between different parts of the "brain" – to optimize performance for various downstream tasks . By fine-tuning these connections, Transformer² can adapt to the complexity of different tasks .
Step 2: Task Detection and Adaptation
Once the model has fine-tuned its internal connections, it needs to figure out what kind of task it's facing. To do this, Transformer² employs one of three strategies :
Prompt-based adaptation: A "scheduling system" analyzes the user's query to identify the attributes of the task. This analysis guides the model in selecting the appropriate "expert" vectors for the task.
Classifier-based adaptation: A classifier categorizes the task, allowing the model to activate the relevant expert vectors.
Mixture-based adaptation: For more complex tasks, the model dynamically combines multiple expert vectors to generate a more nuanced response.
This two-pass mechanism, combined with the use of expert vectors, allows Transformer² to efficiently address a wide array of tasks. These expert vectors are trained using reinforcement learning, with each vector specializing in a specific type of task.
Advantages of Transformer²
Transformer² offers several key advantages over traditional fine-tuning methods:
Dynamic Adaptability: Transformer² can adjust its behavior based on changes in the operating environment or internal states without external intervention.
Parameter Efficiency: Compared to methods like LoRA, SVF achieves higher performance with fewer parameters. This efficiency stems from its focus on modifying singular components of the weight matrices instead of altering the entire model.
Modular Capability: The expert vectors in Transformer² are modular, like building blocks that can be combined and rearranged to adapt to different tasks.
Reduced Overfitting: By selectively adjusting weights, it minimizes the risk of overfitting, a common problem with traditional fine-tuning methods where the model becomes too specialized to the training data.
Improved Efficiency: Transformer² reduces the computational burden associated with fine-tuning, offering a scalable and efficient solution for self-adaptation.
Dynamic Scaling: Transformer² can scale its compute dynamically at test time, meaning it uses more resources for complex tasks and fewer for simpler ones. This dynamic scaling capability allows the model to optimize resource utilization and avoid unnecessary computational overhead.
Comparing Transformer² with Other Approaches
Traditional fine-tuning methods for LLMs are often computationally expensive and inflexible when dealing with diverse tasks. One popular alternative is Low-Rank Adaptation (LoRA), which updates small, task-specific matrices while keeping the rest of the model's parameters fixed. While LoRA reduces the computational cost of fine-tuning, it can be more susceptible to overfitting and may not scale efficiently across different tasks.
Transformer², with its SVF method, surpasses LoRA in efficiency and task-specific performance while requiring fewer parameters. It offers a more dynamic and versatile approach to adapting LLMs to various tasks.
Future Research Directions
Transformer² opens exciting possibilities for future research:
Model Merging: Exploring techniques to combine different expert models into a more powerful unified model, potentially leading to even greater adaptability and performance.
Specialized Applications: Investigating how to extend CEM methods to address more specialized fields and complex tasks, pushing the boundaries of what LLMs can achieve.
Continual Learning: Enhancing Transformer²'s ability to learn continuously and adapt to new information without forgetting previously acquired knowledge, moving closer to the ideal of lifelong learning in AI.
Explainability: Developing methods to understand and interpret the dynamic adaptation process of Transformer², making its decision-making more transparent and trustworthy.
Lifelong Models: Further exploring the concept of self-adaptivity to create "lifelong models" that can continuously evolve and align with the ever-changing nature of the real world. This could lead to AI systems that are more robust, versatile and better equipped to handle real-world complexities.
Limitations and Challenges
While Transformer² represents a significant advancement, it's important to acknowledge its limitations:
Data Requirements: Generating "z-vectors" in real-time can demand substantial amounts of data, which may be a limiting factor in certain applications.
Computational Cost: Although more efficient than traditional methods, the real-time generation of "z-vectors" still requires considerable computational resources.
Memory Footprint: Storing the decomposed UV matrices from the weight matrix W could potentially double the memory footprint, posing challenges for deployment on resource-constrained devices.
Conclusion
Sakana AI's Transformer² marks a significant step towards creating more adaptive and efficient LLMs. By dynamically adjusting model weights in real-time, Transformer² allows LLMs to handle diverse tasks with improved performance and reduced computational costs. This innovative framework embodies the concept of "living intelligence”, enabling continuous change and lifelong learning in AI systems. While challenges remain, Transformer² paves the way for the development of truly dynamic and self-organizing AI systems capable of continuous learning and adaptation. This breakthrough has the potential to revolutionize the field of AI, leading to more robust, versatile and human-like intelligence that can seamlessly integrate into our ever-changing world
Figure 1: Source Sakana AI's Research paper